neuroscience-ai-reading-course
Neighbourhood Cognition Consistent Multi-Agent Reinforcement Learning
Overview :
Introduces Neighbourhood Cognitive Consistency (NCC) in MARL methods. Uses NCC in deep Q-learning and Actor Critic algorithms
Method :
- The multi agent environment is represented as a graph with agents as nodes and the edges representing the relationship between two agents
- Neighbouring agents include those directly linked to the agent, represented by N(i) and form a neighbourhood
- Cognition of an agent is defined as it’s understanding of the environment which includes the observations of neighbouring agents and understanding developed on the basis of that
NCC-Q :
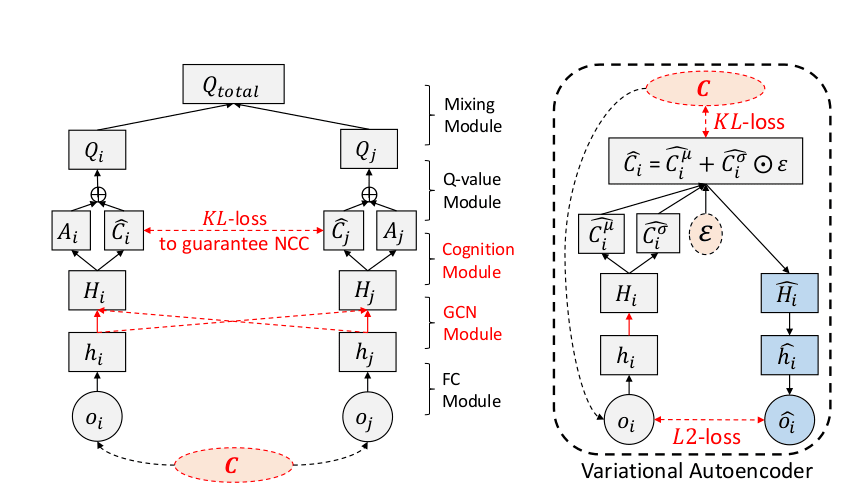
- Assuming the system consists of two agents i and j.
- The observations of both the agents oi and oj are encoded into cognition vectors hi and hj containing agent specific information
- The GCN module aggregates all hi and hj into high level cognition vectors Hi and *Hj.*
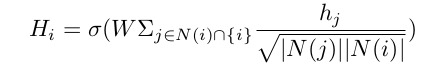
- The next module known as cognition module decomposes H into two braches : A - agent specific cognition and C - Neighbourhood specific cognition
- Next, the Q-value model does element wise summation for aggregating A and C to develop and agent specific Q function Q(o,a).
- The mixing model further sums up the Q value functions of all the agents to form a final Qtotal(o,a) functions
Approach to Neighbourhood Cognitive Consistency :
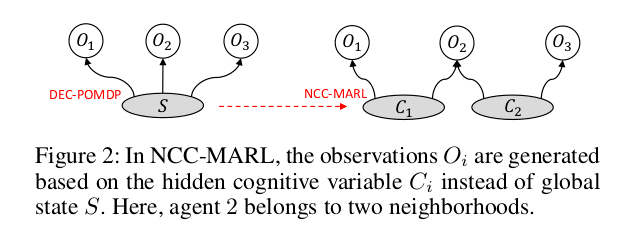
- Assumption 1 : The global state S is *decomposed into several hidden cognitive variables *C. Each neighburhood has one hidden cognitive variable and an agent derives it’s observations from the cognitive variables of all the neighbourhood it belongs too.
- Assumption 2 : If the neighbouring agents are able to learn the hidden cognitive variable, the form consisten neighbourhood cognition
Training the NCC-Q :
The loss functions used are :
- TD-Loss : Calculated over all the agents and incentivises the agents to form a higher Qtotal
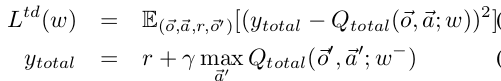
- CD-Loss (Cognitive-dissonance loss) : Specified for each agent. Ensures good cognitive consistency can be achieved at neighbourhood level
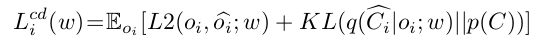
NCC-AC :
Each agent i adopts an independent actor $μ θ i (o i )$
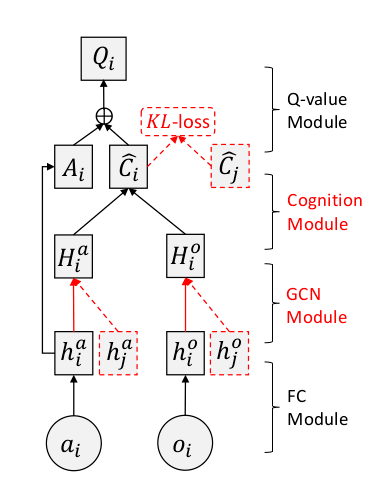
The GCN module and the cognition module are designed for the critic to achieve neighbourhood cognitive consistency and good agent cooperation
Training NCC-AC :
Similar to the training of NCC-Q
Experiments :
- Packet routing: The routers are controlled by NCC-AC. Goal - minimize the Maximum Link Utilization in the whole network (MLU). Observations - flow demands in its buffers (for each individual router). Actions - flow rate assigned to each available path. Reward - 1 on successfully minimizing MLU.
- WiFi Configuration: Access Points are controlled by NCC-Qs. Goal - Maximize the accumulated Recieved Signal Strength Indication (RSSI). Observations - radio frequency, bandwidth, the rate of package loss, the number of band, the current number of users in one specific band, the number of download bytes in ten seconds, the upload coordinate speed (Mbps), the download coordinate speed and the latency. Actions - the actual power value specified. Rewards - RSSI
- Google Football: NCC-Q is evaluated in various scenarios like 2 vs 2 or 3 vs 2. Goal - Learn to play football in a physics based simulator. Observation - Game state determined by player/ball positions and player/ball directions. Actions - Set of 21 discrete actions like move up, move down, different types of kicks and so on. Reward - +1 on scoring a goal, -1 on conceding a goal
Results :
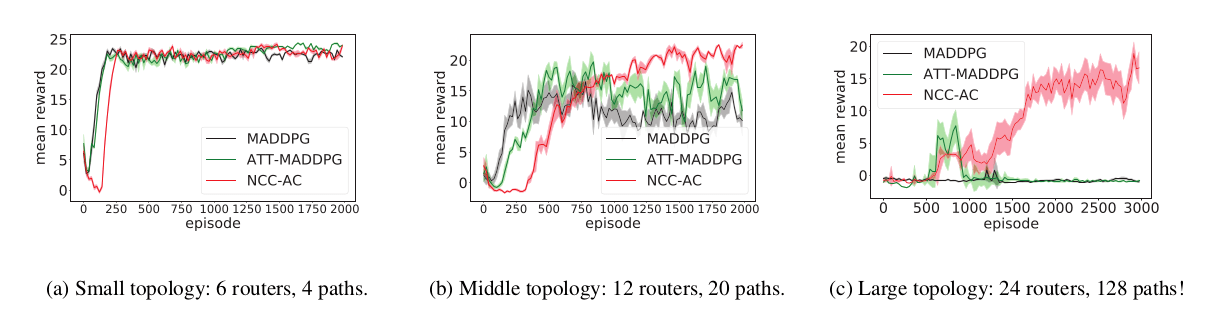
- Packet Routing : NCC-AC can obtain more rewards than the state-of-the-art ATT- MADDPG and MADDPG
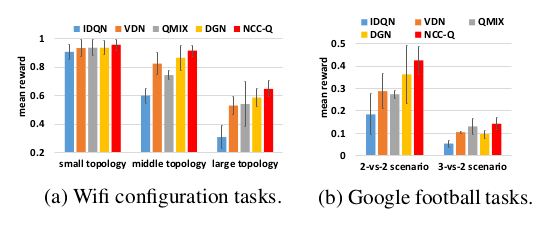
- WiFi Configuration and Google football : NCC-Q always obtains more rewards than all other methods in different topologies for both tasks
Conclusion :
This paper introduces two neighbourhood cognition consistent RL methods namely NCC-Q and NCC-AC which not only outperform SOTA methods but also are capable of achieving good scalability in routing tasks.