neuroscience-ai-reading-course
Modelling Selective-Attention with Neural Networks
PART 1 : A QUICK OVERVIEW OF ATTENTION
Attention has been a fairly popular concept and a useful tool in the deep learning community in recent years, it is essentially giving appropriate weightage to particular segments of your input.
The Motivation Behind Attention
The intrinsic motivation behind attention is the fact that humans are motivated by how we pay visual attention to different regions of an image or correlate words in one sentence.
We can explain the relationship between words in one sentence or close context. When we see “eating”, we expect to encounter a food word very soon. The colour term describes the food, but probably not so much with “eating” directly.
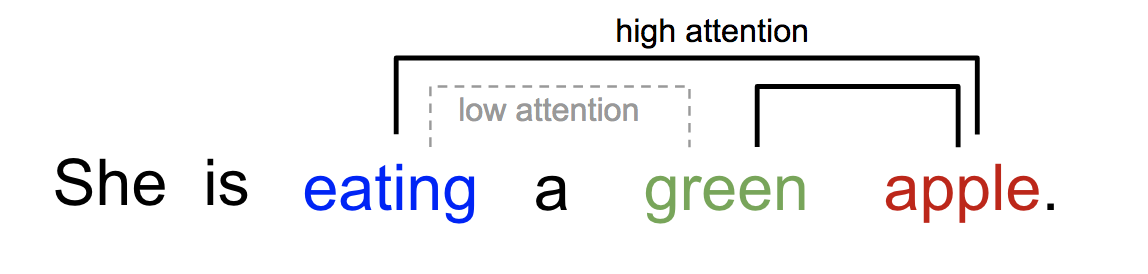
The attention mechanism was born to help memorise long source sentences in neural machine translation (NMT). Rather than building a single context vector out of the encoder’s last hidden state, the secret sauce invented by attention is to create shortcuts between the context vector and the entire source input. The weights of these shortcut connections are customisable for each output element.
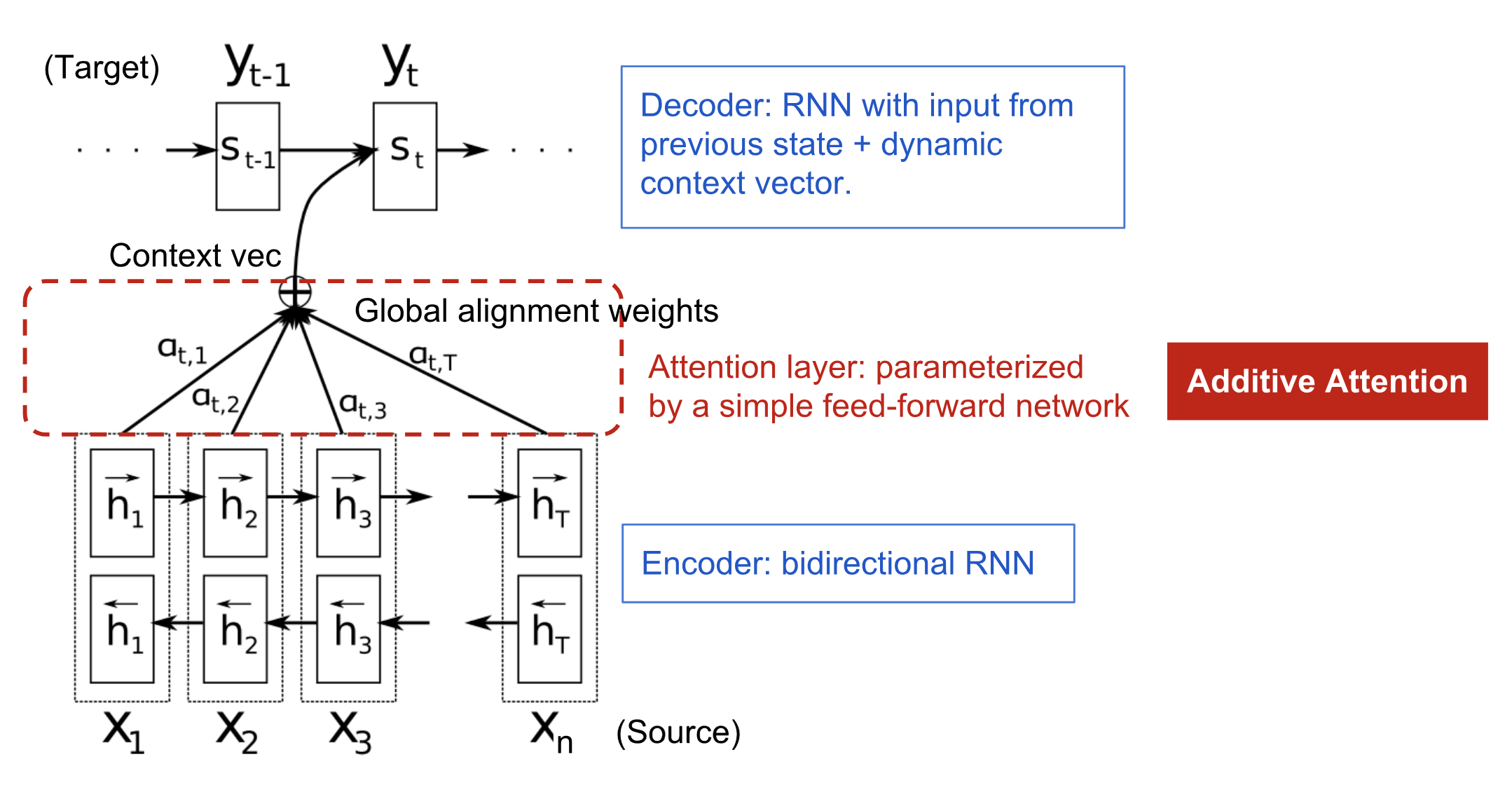
Fig. 4. The encoder-decoder model with additive attention mechanism in Bahdanau et al., 2015.
What exactly is attention ?
Let us understand it with Neural Machine Translation
The alignment model assigns a score to each pair of input at position and output, based on how well they match. These scores are therefore weights defining how much of each source hidden state should be considered for each output.
The matrix of alignment scores is a nice byproduct to explicitly show the correlation between source and target words.

Fig. 5. Alignment matrix of “L’accord sur l’Espace économique européen a été signé en août 1992” (French) and its English translation “The agreement on the European Economic Area was signed in August 1992”. (Image source: Fig 3 in Bahdanau et al., 2015)
For further understanding you can visit this article
How can it be used apart from NMT ?
This is an example for image captioning and attention is used to assign weight to convolutional features extracted from the image !

PART 2 : BOTTOM-UP & TOP-DOWN VS. PRIORITY MAP THEORY OF SELECTIVE ATTENTION IN COGNITIVE NEUROSCIENCE
Selective attention plays an essential role in information acquisition and utilisation from the environment. In the past 50 years, research on selective attention has been a central topic in cognitive science.
Selective attention is involved in the majority of mental activities, it is used to control our awareness of internal mind and of the outside world and it helps us integrate the information from multidimensional and multimodal inputs. Selective attention is predominantly categorised by psychologists and neuroscientists into “endogenous” and “exogenous” attention.

Exogenous attention
Endogenous attention
To understand the mechanisms underlying selective attention is helpful for computational models of selective attention for different purposes and requirements. However, theories in the field of human selective attention are complex and non-unified.
The mainstream view of selective attention proposes that there exist two complementary pathways in the brain cortex, the dorsal and ventral systems. The former, which includes parts of the intraparietal sulcus (IPS) and frontal eye field (FEF), is in charge of the top-down process guided by goals or expectations. The latter, which involves the ventral frontal cortex (VFC) and right temporoparietal junction (TPJ), is in charge of the bottom-up process triggered by sensory inputs or salient and unexpected stimuli without any high-level feedback.
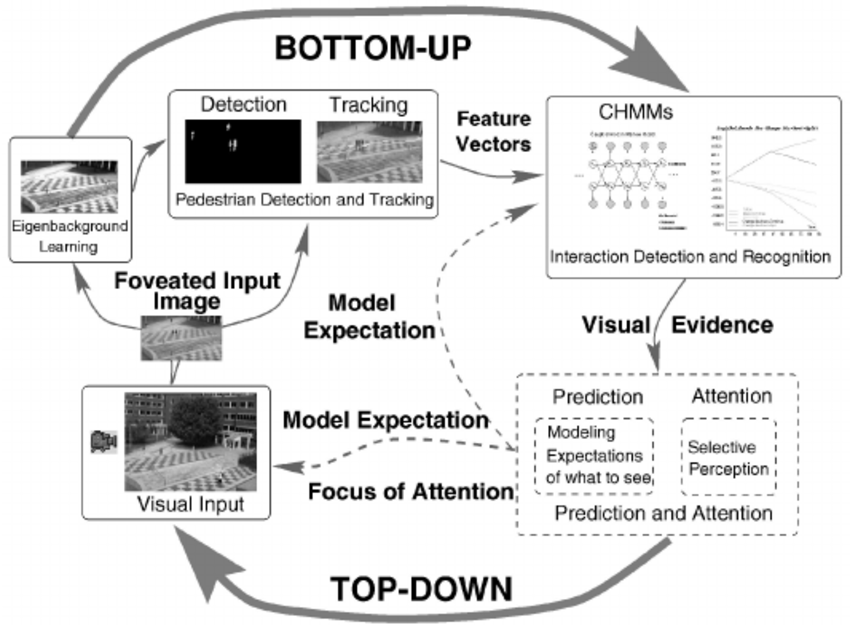
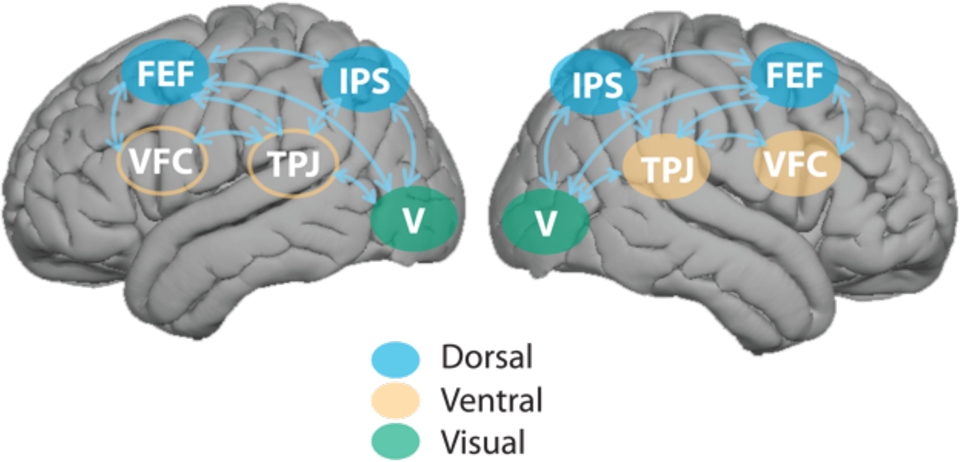
The classic bottom-up and top-down control theory can explain many cases in selective attention, and lots of computational models are based on this simple theoretical structure. However, in some cases, for instance, stimuli with the same physical salience but associated with reward or emotional information can also capture attention, even if not correlated with the current goal.
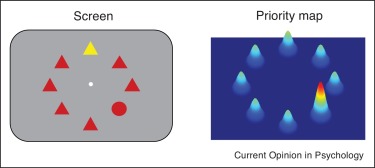
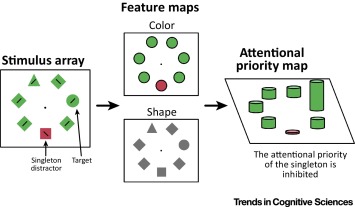
Thus, beyond the classical theoretical dichotomy, the priority map theory remedies the explanatory gap between goal-driven attentional control and stimulus-driven selection by adding the past selection history to explain some strong selection biases. The aim of a priority map is to represent topographically the relevance of the different parts of the visual field, in order to have an a priori mechanism for guiding the attentional focus on salient regions of the retinal input. The focused region will be gated, so that only the information within it will be passed further to the higher level and will be processed.
In general, these two theoretical frameworks are helpful to explain most behavioral cases of selective attention.
Apart from Attention Models in Computer Science other theories include :
- Functional Neural Networks
- Neural oscillation model
- Free-energy model and information theory
Conclusion
We conclude in this section that human attention is a process to allocate cognitive resources with different weights according to the priority of the events. Similarly, in computer science, attention mechanisms in models are designed to be allocating different weights to relevant input information and ignore irrelevant information with low-valued weights. However, the connection between computer science models and psychology is still loose and broad. It is required to explore the human cognition processing from a computational perspective, which is also beneficial for confirming psychological and biological hypotheses in computer science.
References
- Chorowski, Jan K., et al. “Attention-based models for speech recognition.” Advances in neural information processing systems. 2015.
- Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” International conference on machine learning. 2015.
- Di Fu, Cornelius Weber, et al. “What Can Computational Models Learn From Human Selective Attention? A Review From an Audiovisual Unimodal and Crossmodal Perspective.” Frontiers in Integrative Neuroscience 14 (2020).
- Yu, Hongliang, et al. “Temporally selective attention model for social and affective state recognition in multimedia content.” Proceedings of the 25th ACM international conference on Multimedia. 2017.