An open source implementation of Neural Voice Cloning with Few Samples
This page provides audio samples from the speaker adaptation approach of the open source implementations Neural Voice Cloning with Few Samples.
The model is first trained on 84 speakers. Then the model is adapted to a particular speaker to generate clone samples
Speaker Adaptation
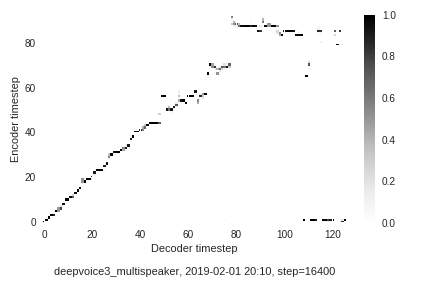
- Samples from the Multi-Speaker Generative model trained on 84 speaker (~20 hours) on the VCTK dataset.
- Pretrained model: link
But don't expect anything right.
I won't make an official complaint.
They make a selective perception process.
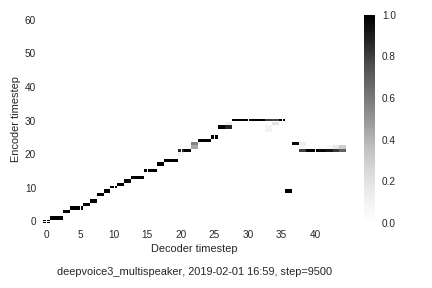
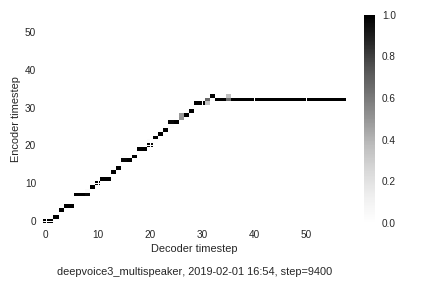
Speaker 85
- Samples from a model adapted to speaker number 85
- Pretrained model: link
Predicted Voices for speaker 85
Players are fighting to stay in the team
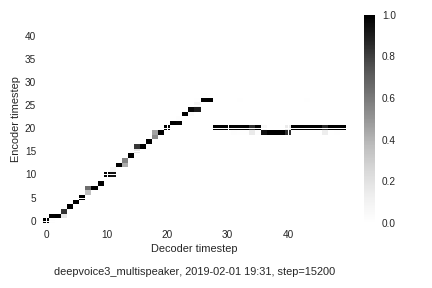
The difference in rainbow depends considerably on the size of the drops and the width of the coloured band increases as the size of the drops increase.
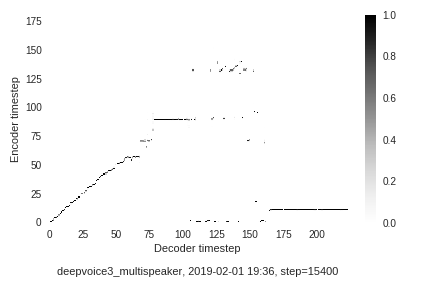
I am not a fan of both.
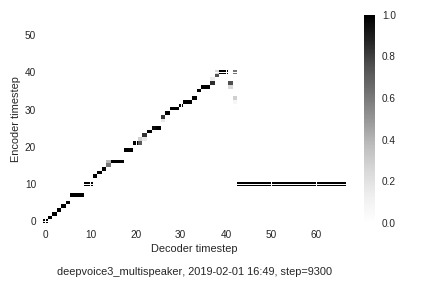
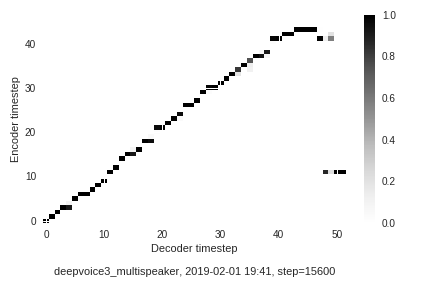
Speaker 86
- Samples from a model adapted to speaker number 86
- Pretrained model: link
Predicted Voices for speaker 86
The auction will be held tomorrow.

It's too pretty. It's too small.
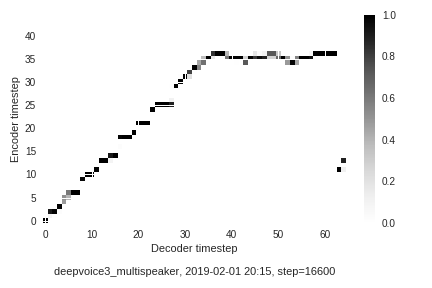
The greeks used to imagine that it was a sign from the gods to foretell war or heavy rains.